前言
这篇故障从原因来看比较简单,但分享出来的原因是因为在分析故障原因的过程中忽略了一些关键因素,导致走了一些弯路,所以写出来供大家借鉴。
故障现象
上周负责的系统出现了一次故障,故障的表象是部分搜索超时严重。在对监控进行排查的时候,发现有一台服务器CPU使用率有比较大的飙升,为了不影响业务,先将此服务器重启。重启后,CPU使用率恢复正常,故障恢复(见下图)。
故障原因分析过程
剩下的事情就是对故障原因进行分析了,是什么原因导致了请求的超时呢?
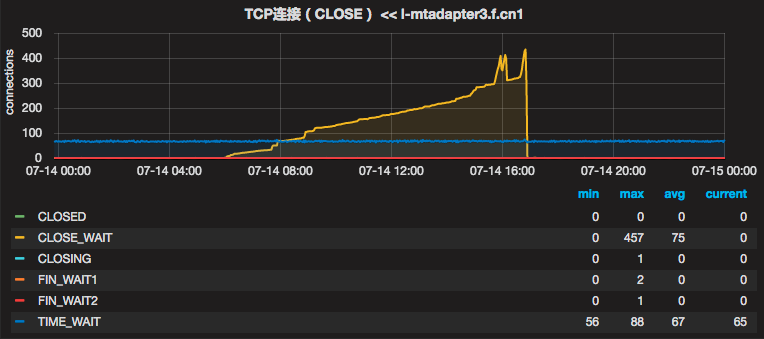
于是查看其它的监控,发现CPU使用率异常的服务器在相似的时间点,出现了大量的CLOSE_WAIT,这时立马警觉起来。我们都知道,TCPIP断开连接要经历4次挥手的过程,如下图:

从上面这个图我们可以看出,CLOSE_WAIT状态是由于对端主动断开了连接导致的。在我们的这个case中,我们的系统是client端,那也就意味着,是server端主动断开了与我们的连接,而正常情况client端应该继续发送ACK和FIN指令完成4次挥手过程的,但很显然我们的系统并没有继续后续的挥手,开始查找原因。
由于系统中使用了AsyncHttpClient组件(以下简称AHC),开始时怀疑是AHC使用不当造成的。比如如果在AHC的时候使用流处理,而在处理流的时候出现异常,很有可能导致连接不能关闭而导致CLOSE_WAIT出现。但排查代码确认我们的系统中没有使用流,此原因排除。
考虑到我们的异步请求是通过继承AsyncCompletionHandler抽象类来实现异步结果的处理,于是开始确认onCompleted和onThrowable方法是不是有一些特殊处理导致连接没有关闭,但看代码也没发现有什么问题。于是“排除”了自己代码的原因。这里用双引号是因为其实并没有真正排除代码的问题,而是忽略了一处有问题的代码。这里先卖个关子。
后面开始怀疑是否是AHC的bug导致,于是放狗(google)查资料,在AHC的issue讨论区也看到有人反馈CLOSE_WAIT的情况,但对方是在大访问量的情况下会导致CLOSE_WAIT出现(issue链接),但这个issue也没有得到AHC官方确认。考虑到我们的系统QPS不是很高,所以也排除了bug的可能性。
继续放狗,看到一篇博客(链接)讲netty里面的autoread特性会导致CLOSE_WAIT出现,但autoread是netty4里面的特性,我们使用的AHC依赖的是netty 3.10,这个原因也排除了。
至此,线索中断,于是求助余老师。PS:上面的那博客其实就是余老师写的,😆
余老师了解了情况之后,首先询问AHC是否使用的非单例(如果创建多个AsyncHttpClient实例是有可能导致大量CLOSE_WAIT的),答案是没有。
继续询问使用AHC的线程中是否使用了阻塞,答案是没有。
到这里,余老师也没给出更进一步的建议,所以继续排查。
第二天已经是周末,余老师继续帮忙定位问题,在看代码时发现有个地方的缓存使用了HashBasedTable,而HashBasedTable是非线程安全的,因为它使用了HashMap实现的,于是怀疑是这个地方可能会有问题。通过查看监控,发现故障时CPU、Load是同时增长的,而且CPU使用率在25%左右,基本可以确定在当时某个线程CPU使用率达到100%(服务器是4核)。
通过代码和监控的关联,可以确定这次故障的原因是因为使用了非线程安全的HashBasedTable,导致竞态条件下踩中了HashMap的坑导致当前线程CPU使用率100%,这样当前线程也就没有时间来处理后续的网络事件了,比如断开连接,最终导致大量CLOSE_WAIT以及超时出现。
1 | private final Cache<String, Table<String,String,PackageFlightBean>> packageListBeanCache = CacheBuilder.from(packageListSpec).build();//<key,<code,PackageFlightBean>> |
总结
这次故障原因分析的过程走了一些弯路,原因有这么几点:
1.没有及时发现某个线程CPU使用率达到100%的情况:
如果能及时发现这一点,那么很可能就能在第一时间反应到是死循环导致的,那么定位问题会更快一些。当然如果我们的监控系统能够发现某个线程CPU使用率100%并告警就更好了,这个建议已经反馈给OPS同学,他们在想办法做了。那么在现有的情况下,如果我们发现CPU使用率平滑持续在25%左右,那么我们也需要额外注意,因为在4核的系统中,这可能代表某个线程CPU使用率已经在100%了;
2.没有保留现场如线程栈之类的信息:
如果在重启服务之前保留了线程栈,那么定位问题会更方便一些,可惜当时的同学急于修复故障,而未做到这一点;
3.没有发现HashBasedTable的坑:
因为故障系统是个低频应用而且是从别的团队接手过来的,所以对代码不够熟悉,更不知道HashBasedTable是非线程安全的,最终导致故障的出现。这里也提醒一下,Guava里面的HashBasedTable、ArrayTable、TreeBasedTable、StandardTable、StandardRowSortedTable都是非线程安全的,使用的时候务必注意。另外,我们在使用在使用第三方工具的时候,务必要仔细查看相关说明,比如一些限制因素,避免踩坑。