基本功能
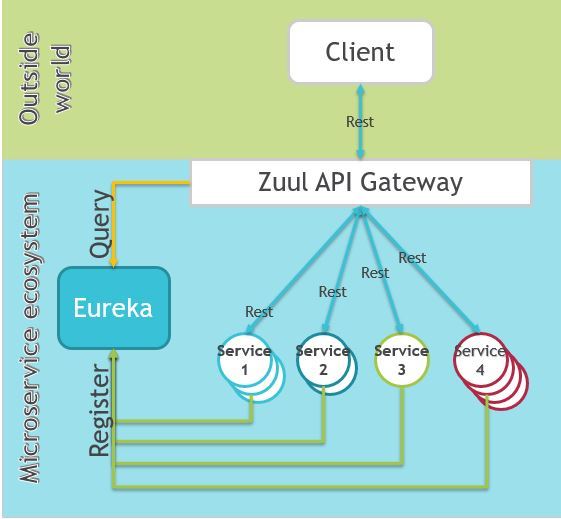
在分布式系统中,服务提供端和消费端彼此不知道对方的存在,因此需要有一种机制来确保消费端能够找到提供端并进行调用。一般来说,提供端需要将自己能够提供的服务信息暴露出来,这样消费端通过检索就能找到自己需要的服务并建立连接进行调用。所以,对于服务提供端来讲,需要具备以下功能:
- 服务注册:将服务信息暴露出来,供消费端查找和使用
- 取消注册:即注销服务的注册信息
同时,对于消费端来说,则需要:
- 服务检索:按一定条件查找服务信息,如按应用、接口、IP等检索
- 服务订阅:订阅特定的服务,为后面的服务调用和治理做前期准备
- 取消订阅:取消指定服务的订阅
结构组成
在这种情况下,注册中心的概念就被提了出来。
同时,系统间调用需要能够根据服务的运行状态(如上下线状态、负载、响应时间、网络情况等)而灵活调整调用端与服务端的组合。